在持续了一年多的“百模大战”后,近期,AI巨头们终于开始近身肉搏、疯狂降价,类似于很多传统行业,AI行业也开启了以价格换市场的老套路。
很多人可能不太清楚,本轮大模型降价的第一枪,是一家金融公司开打的。
5月初,著名量化私募幻方宣布,旗下的AI公司深度求索DeepSeek发布第二代MoE模型DeepSeek-V2,该模型API定价为每百万Tokens输入1元、输出2元(32K上下文),价格为GPT-4 Turbo的近百分之一。
幻方作为量化领军公司,很早便储备了大量的GPU显卡,本次率先降价,也体现了公司开拓AI业务的决心。
5月13日,全球AI的领军企业OpenAI祭出“王炸”,发布新旗舰模型“GPT-4o”,该模型更接近真人思维,可以实时对音频、视觉和文本进行推理,更重要的是,价格仅为GPT-4 Turbo的一半。从OpenAI过往的动作看,降价也一直是其升级的主旋律。
5月15日,国内AI巨头字节跳动也加入“降价潮”,公司旗下的豆包主力模型为0.8元/百万Tokens,相当于0.8厘/千Tokens,即0.8厘就能处理1500多个汉字,号称比行业价格便宜了99.3%,大超市场预期,也让AI大模型的API调用成本迈入“以厘计价”的时代。
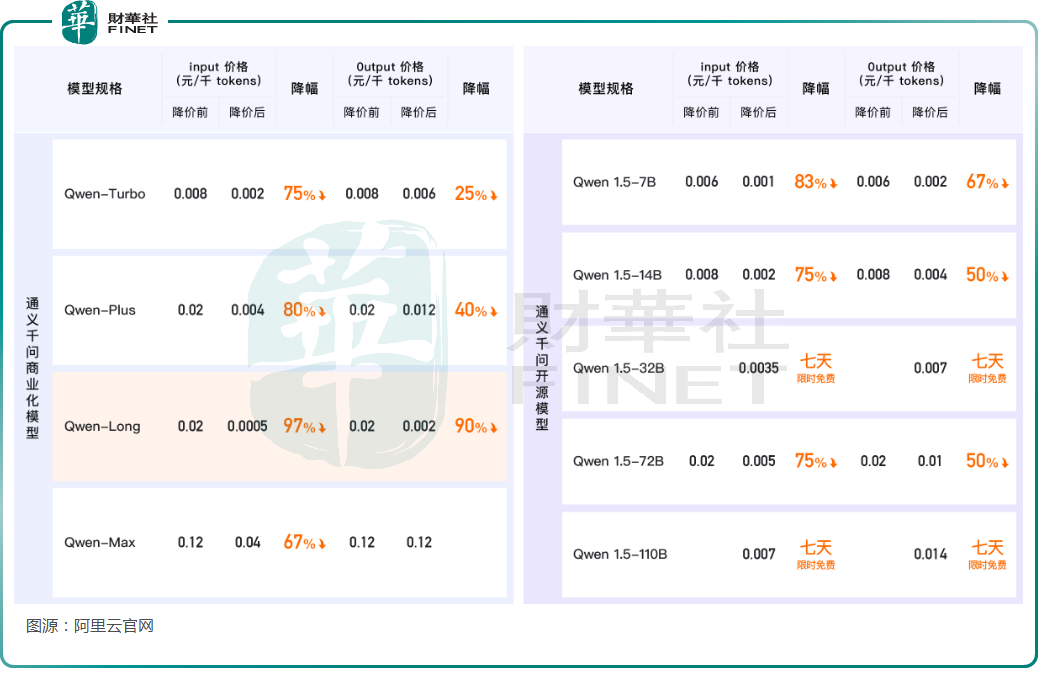
随即,在5月21日,阿里云宣布通义千问大模型降价,其中GPT-4级主力模型Qwen-Long降价幅度达到97%,API输入价格从0.02元/千tokens降至0.5厘/千tokens。这意味着用户以1元钱可以买200万tokens,相当于5本《新华字典》的文字量。
与此同时,一直押宝人工智能的百度,宣布文心大模型的两大主力模型ERNIE Speed和ERNIE Lite全面免费,立即生效。据悉,这两款模型支持8k、128k上下文长度,是目前百度文心大模型系列中服务用户最多的模型型号。
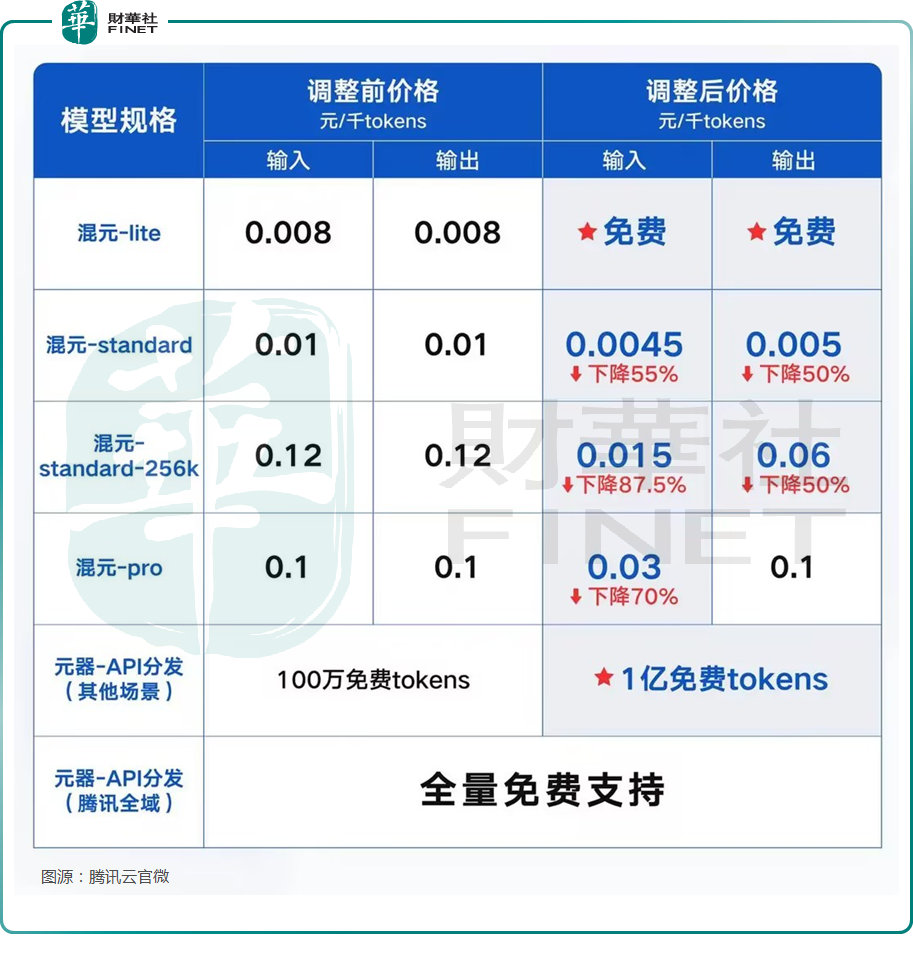
5月22日,腾讯云公布全新大模型升级方案,旗下主力模型之一混元-lite模型,API输入输出总长度计划从目前的4k升级到256k,价格从0.008元/千tokens调整为全面免费。混元-standard API输入价格下降55%,API输出价格下降50%。新上线的混元-standard-256k,API输入价格下降87.5%,API输出价格下降50%。最高配置万亿参数模型混元-pro,API输入价格降幅达70%。
某种程度上,大模型降价潮是资本涌入、市场竞争之下的必然产物。未来,能够提供更高性价比服务的企业将脱颖而出,而无法适应变化的企业则可能出局或被整合并购。
过往来看,每一轮科技进步都伴随着边际成本的下降和生产效率的大幅提升。
比如芯片的诞生,将计算的边际成本降到了趋近于零。随后引发了计算机革命,出现IBM、惠普等科技巨头。互联网的诞生,将分发的边际成本降到了几乎为零,继而引领了互联网革命,出现了亚马逊、谷歌和Meta等科技巨头。
而AI技术也是一次生产力革命,目前受限于模型推理成本较高,AI应用普遍面临较大的成本压力。
本轮大模型的降价,本质上是将创造的边际成本大幅度下降,后续开发者可以降低开发成本,更高效地开发AI应用,缩短开发周期,从而推动AI应用场景大规模的涌现。从这个意义上,大模型的降价,或是打开AI应用的关键“开关”。
知名企业家李开复认为,今年会是大模型应用的爆发元年。腾讯研究院亦认为,行业大模型有望加速在传统行业落地应用,并在云智一体的基础设施支持下,朝多模态、人工智能体、端侧及小型化等方向发展,更深入地嵌入各行业的工作流程中,从而促进生产力的提升。英伟达首席执行官黄仁勋此前就曾表示“下一场工业革命已经开始”。